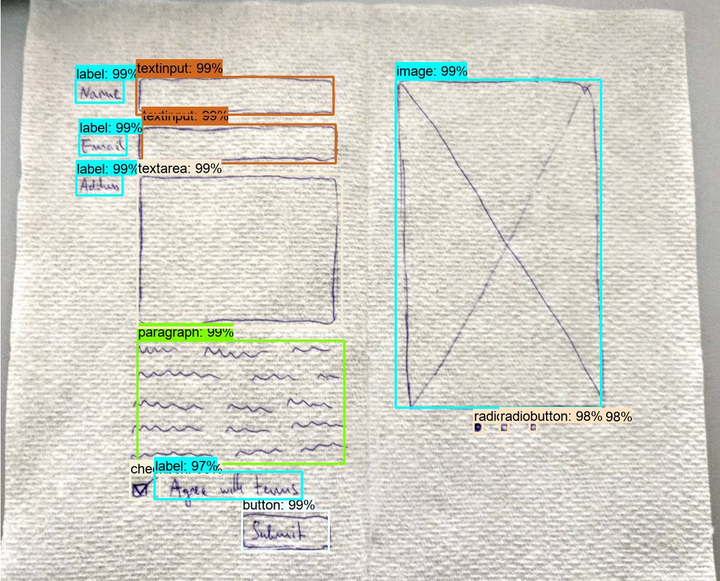
 DrawnUI element detection
DrawnUI element detection
We achieved $2^{nd}$ rank in the hackathon.
The aim of this hackathon was to localise and identify several different HTML UI elements in hand-drawn wireframe drawings of websites as well as for screenshots of real websites.
The dataset provided for the hackathon contained about 3200 wireframe drawings of websites. The goal was to identify the different HTML UI elemnents present in the image, such as “Text Box”, “Button”, “Image”, etc. Hence, it boiled down to an object detection problem. It also included another dataset containing screenshots of real websites. The problem remained the same for both the datasets.
We used several different Object Detection techniques and decided on using the just released SOTA model YOLOv5. We tried different flavours of YOLOv5 and since inference time was not a bar, we went ahead with the XL version of the same to boost performance. We also used pre-trained weights and performed a LR scheduler study to boost the scores even further.
We also observed that our model was giving out good predictions for the common elements with high confidences, but was not giving outputs for the more uncommon elements. Hence, we performed a study to change the confidence cutoff levels to optimise it for the use case and adjust it according to the distribution in the data. This allowed us to achieve near-perfect performance level of 0.95 F1 score on the validation set.
The solution built was performing really good on unseen test images managing an mAP value of 0.82. This model was later swapped with the last year’s model in the already developed pipeline to allow rapid prototyping of websites and dashboards.
Prasang Gupta
Senior Associate, Emerging Technologies
My research interests include distributed robotics, mobile computing and programmable matter.
