Zero-Shot Deepfake Audio Generation
[ PwC US ] Anudeep Immidisetty, Amelia Bauer, Prasang Gupta
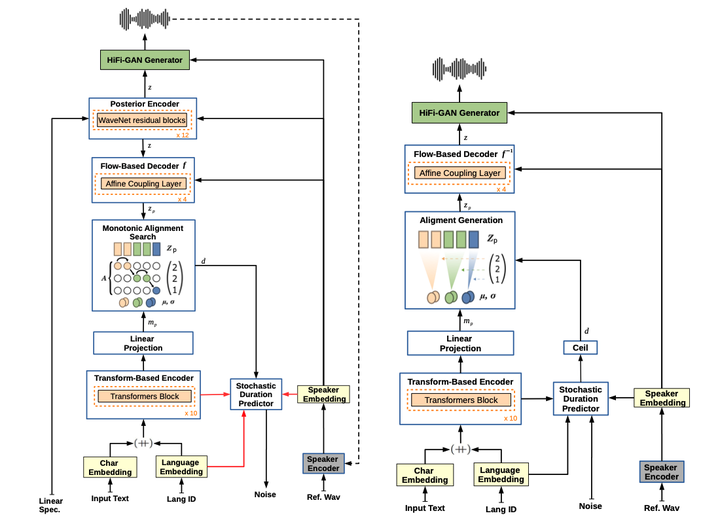 A representation of YourTTS model architecture used in the study
A representation of YourTTS model architecture used in the study
The aim of this project was to create a demo for generating speech from text in the voice of the user given the least amount of sample possible.
As the aim of this study was to create a demo, we chose to go ahead with Zero-Shot model as it takes practically no time to train and can start giving good results even with very little amount of sample data. The tradeoff with accuracy was accepted in favour of time. We tested different models, the most popular being YourTTS, SCGlowTTS and SV2TTS. On the basis of qualitative assessment on the representative test dataset, which included both male and female audio samples in 3 different accents (American, British and Indian), YourTTS model was selected as the clear winner.
After finalising the model, this was tested further for robustness and a minimum sample audio time was estimated based off of these tests and it came out to be 1 minute for getting decent results in most cases. We then deployed this solution on an internal hosting site and created an interactive demo using our developed model as the backend. A representative set of 10 small sentences were obtained which contain as many different phonetics as possible and then a feature was added to record the user speak these sentences.
After running these samples through the model, which takes about a minute, the user would be able to hear their deepfake speaking 5 different sentences that were not a part of the representative set in their voice. This rounded off a user-friendly demo that can be used for GTM strategies.
Prasang Gupta
Senior Associate, Emerging Technologies
My research interests include distributed robotics, mobile computing and programmable matter.