Contract Lifecycle Management (CLM)
[ PwC US ] Shyam Choudhary, Vishal Bhutani, Prasang Gupta, Brian Kravcik, Shantanu Dev, Joseph Voyles
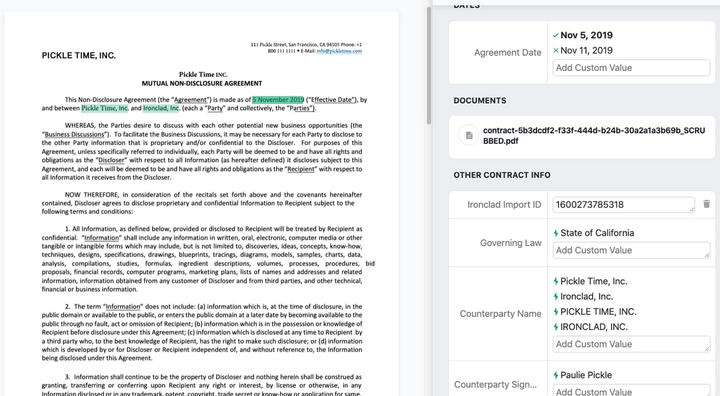 Representation of contract information extraction (Google Cloud)
Representation of contract information extraction (Google Cloud)
The client wanted to switch from legacy contract management tool to a new vendor. However, they were not confident of the metadata they had for the contracts and wanted help in getting all the major information extracted from the documents. They also wanted hierarchical linkages for most of the contracts for better organisation in the new tool.
We solved the first problem with a myriad of different tools. These included advanced NLP models for entity extraction based on transformers, tree based ML models for certain classifications and logic-driven string search models.
Common fields that are present in almost every document were extracted using a trained NER model linked with an active learning pipeline. These models were built using a modified version of PURE, an open source offering by Princeton NLP. The active learning pipeline was built using LabelStudio as a frontend for manual annotations to get initial training data and then subsequently, for getting labels for the most uncertain samples.
Fields which had only a few possible values like “Agreement Type”, were trained using a simple Random Forest classifier. The training data was obhtained using a mix of string extractions from the filenames and the existing contract metadata provided by the client. This, combined with the NER model resulted in boosted accuracies for this field.
We built logic-based string search models for those fields which were not abundantly present and were more situational. These included fields like “Force Majeure” and all fields associated with this, “Termination Payments”, etc. This helped us extract information for these fields for the majority of the documents they were present in with little overhead.
All of these extractions were provided to the client and after spot-checking and QA, were used in the construction of hierarchical linkages. Strong linkages were built by extracting the reference phrase within contracts that contains the details regarding the parent or the child contract. These were then translated back to the database we had. Weak linkages were also built based off of logic to combine documents under each MSA umbrella wherever the extraction of the reference phrase wasn’t possible.
The extractions provided to the client passed the QA test with about 90% accuracy. Also, we managed to provide hierchical linkages for more than 75% of the documents provided to us that could be linked.
This has historically been a manual-only job with several hours of manpower invested in reading through the huge contracts and extracting information. We accelerated this process by appending this with models wherever possible. This reduced the load on the manual annotators and we were able to complete this in a fraction of the time that would’ve been invested in an all-manual project saving roughly 30,000 hours and $750,000 for the client.
Prasang Gupta
Senior Associate, Emerging Technologies
My research interests include distributed robotics, mobile computing and programmable matter.