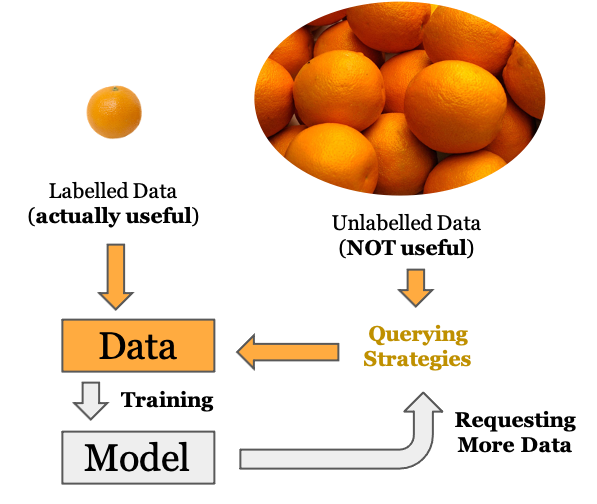
 Active learning flow
Active learning flow
The aim of the study was to build out a pipeline for active learning that other projects with scarce labelled data will leverage for model building. It also included trying the effectiveness of active learning on a standard dataset and evaluate different techniques.
The dataset chosen for this study was CIFAR10. This dataset contains 60,000 32x32 images with 10 unique classes. We used a maximum of 10,000 images at each time for training purposes. This study’s focus was to compare the performance of active and passive learning using same number of labelled samples.
The passive learning model would be trained on a uniform distribution of the dataset size, however, the active learning model would be initialised with half the training size and then would be trained for the full size by sequential queries. We tried 3 queries in this study : uncertainty, margin sampling and entropy sampling. We achieved better performance with active learning for all the sizes, however, the improvement in performance varied from as low as 1% to a sizable 23%. The details for all the experiments and the queries can be seen in the slides.
The pipeline developed from this project was consecutively used in multiple client projects to improve the modelling capabilities and thrive wherever manually labelling the full dataset was not an option.
Prasang Gupta
Senior Associate, Emerging Technologies
My research interests include distributed robotics, mobile computing and programmable matter.